import timm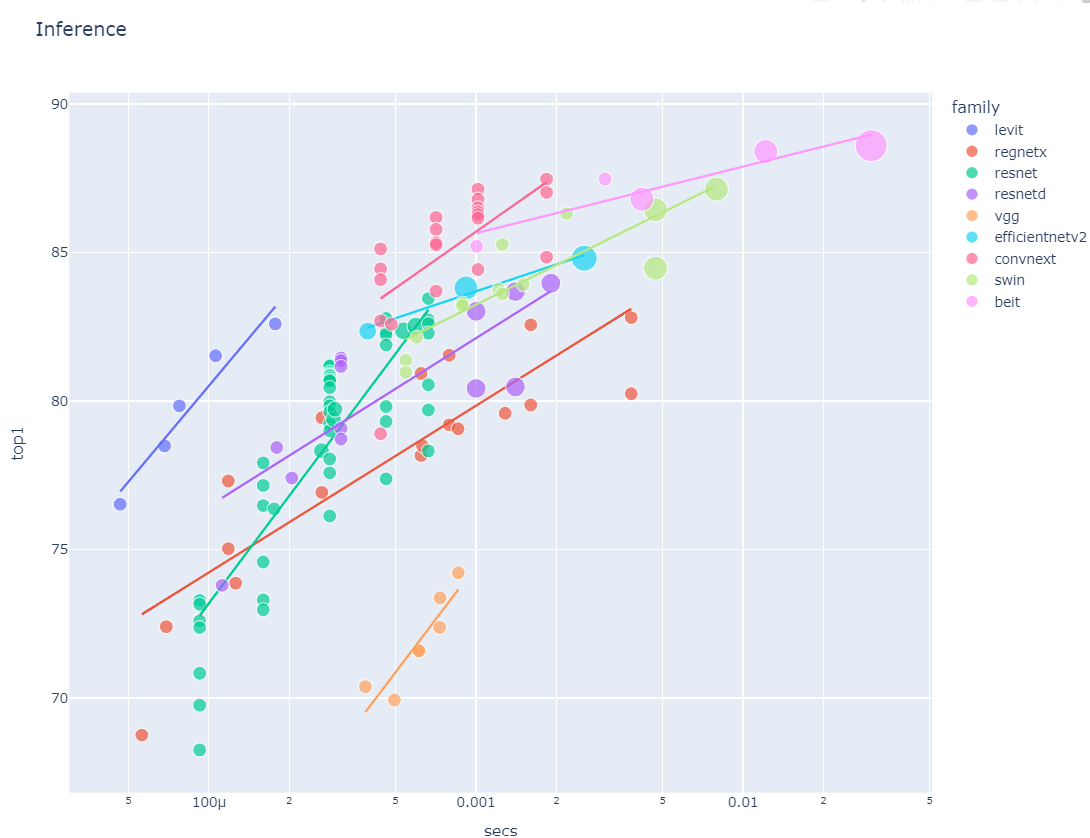
Today I’ll go through how to find and test different deep-learning architectures from Pytorch Image Models (timm) library made available here by Ross Wightman and use them in our models.
1. Using timm - PyTorch Image Models
1.1 Introduction
What are timm’s models? They’re mathematical functions (i.e. application of matrix multiplication, non-linearities e.g. ReLu’s)
Reference: “Which image model are best” - Jeremy Howard
Reference: “timm” - Ross Wightman
We want to know 3 things:
1. how fast are they? You’d want models in top left of chart.
2. how much memory?
3. how accurate are they? Lower error rate the better.
[Future iteration I]: A formalised metholodgy to decide what is fast enough, appropriate memory-use, and what is accurate enough for our use-cases.
There is a useful high-level chart from Jeremy’s notebook charting accuracy (Y-axis) vs secs per sample (X-axis):
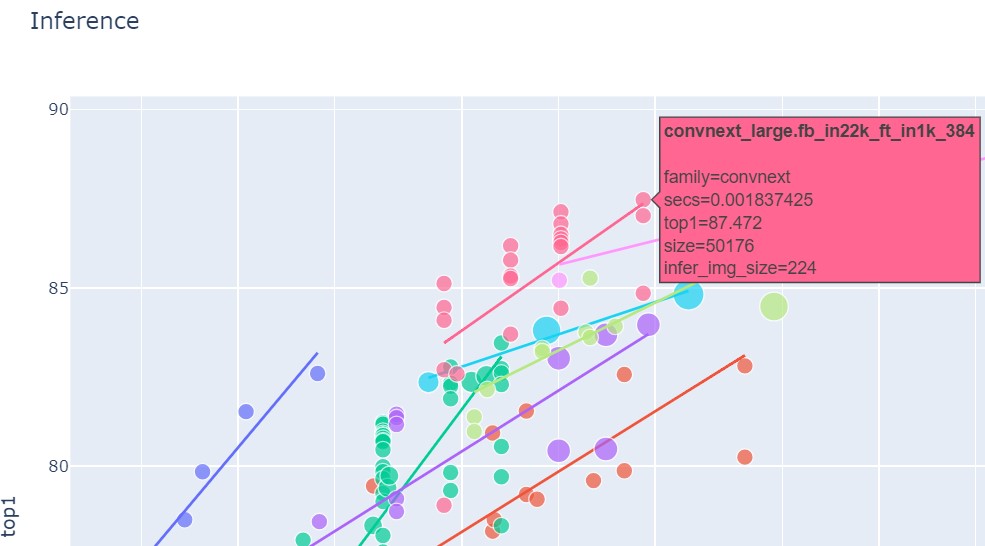
I chose to use a model from the convnext family due to its balance of high accuracy and speed.
[Future iteration II]: Some more formalised methodology on choosing the architecture. Jeremy does mention architecture should be the one last thing things to worry about and he usually builds from resnet and tests whether it is, accurate enough and fast enough, then iterate from there.
1.2 Import timm library
1.3 List available model architectures and choose one
timm.list_models('convnext*') # * wild card searches ['convnext_atto',
'convnext_atto_ols',
'convnext_base',
'convnext_femto',
'convnext_femto_ols',
'convnext_large',
'convnext_large_mlp',
'convnext_nano',
'convnext_nano_ols',
'convnext_pico',
'convnext_pico_ols',
'convnext_small',
'convnext_tiny',
'convnext_tiny_hnf',
'convnext_xlarge',
'convnext_xxlarge',
'convnextv2_atto',
'convnextv2_base',
'convnextv2_femto',
'convnextv2_huge',
'convnextv2_large',
'convnextv2_nano',
'convnextv2_pico',
'convnextv2_small',
'convnextv2_tiny']2. Create your Learner with a timm model
2.1 Get your data
from fastai.vision.all import *
path = untar_data(URLs.PETS)/'images'2.2 Prepare your Functions
def is_cat(x): return x[0].isupper()2.3 Load your DataLoader
dls = ImageDataLoaders.from_name_func('.',
get_image_files(path), valid_pct=0.2, seed=42,
label_func=is_cat,
item_tfms=Resize(192))2.4 Build your Learner
learn_conv = vision_learner(dls, 'convnext_tiny', metrics=error_rate).to_fp16()
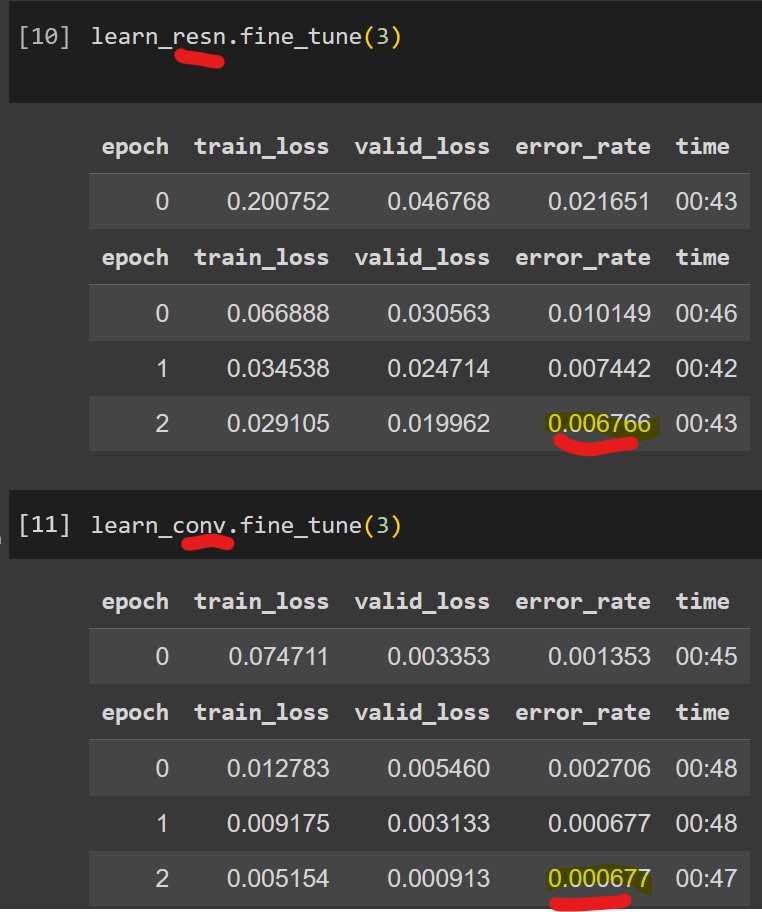
learn_resn = vision_learner(dls, 'resnet18', metrics=error_rate).to_fp16()2.5 Fine-Tune: ResNet18 vs ConvNextTiny
A 90% reduction in the error rate! (0.6766% to 0.0667%: 1-(0.000677/0.006766)). It’s noted that the resnet error rate was quite low and changing the model was probably not necessary.