debv3_tokenizer.save_pretrained("./tokenizer")
model.save_pretrained("./model")
1. Introduction
From Part 1, the Kaggle Competition: U.S. Patent Phrase to Phrase Matching was a notebook competition, that is, a simple csv upload of predictions would not suffice.
A notebook with code needs to be submitted in order to succesfully enter and be graded.
This notebook will have access the kaggles cloud folders to gather the raw data, process and model it. The only catch is the notebook has no access to the internet. This means pip install package will not work.
Thus, the pre-trained models and tokenizers need to be uploaded to the inputs folder, before being installed.
Why? Even though transformers library is available on Kaggle via import, each time a function like AutoTokenizer is called, this accesses the internet to reach the HuggingFace Model Hub and looks for the latest available models.
In order to upload files though, they need to be exported first, but in order for them to be exported, they need to be downloaded first!. Well that is what I figured out, there’s probably a vastly more seemless way but I didn’t go out of my way to find out a way to do it, this way just made the most sense. In the future, I’ll find out a better way.
So, the idea is:
1. create new kaggle noteook with internet access
2. install libraries
3. run our models
4. export our models
5. download our libraries
6. create new kaggle noteook with no internet access
7. upload downloaded libraries and exported models
8. install libraries via uploaded files
9. import pre-trained models vias uploaded files
10. conduct training
11. make predictions 12. export to csv
13. submit notebook
2. Export Model and Tokenizer
3. Download Libraries
Two libraries are required for this notebook to run datasets and transformers
!pip download datasets
!pip download transformers4. Upload File to Kaggle
4.1 Gather files
Place all json files (tokenizer and model) and whl files (libraries) in the same folder.

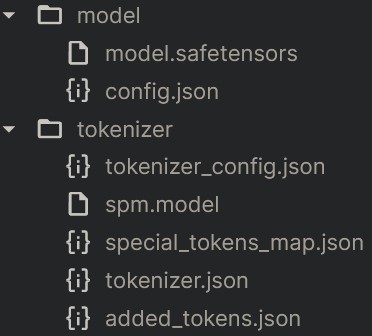
4.2 Kaggle Upload
- Go to [Datasets]
- Then [New Dataset]
- Name a [Dataset Title]
- Choose all files from your local folder
- Click [Create]
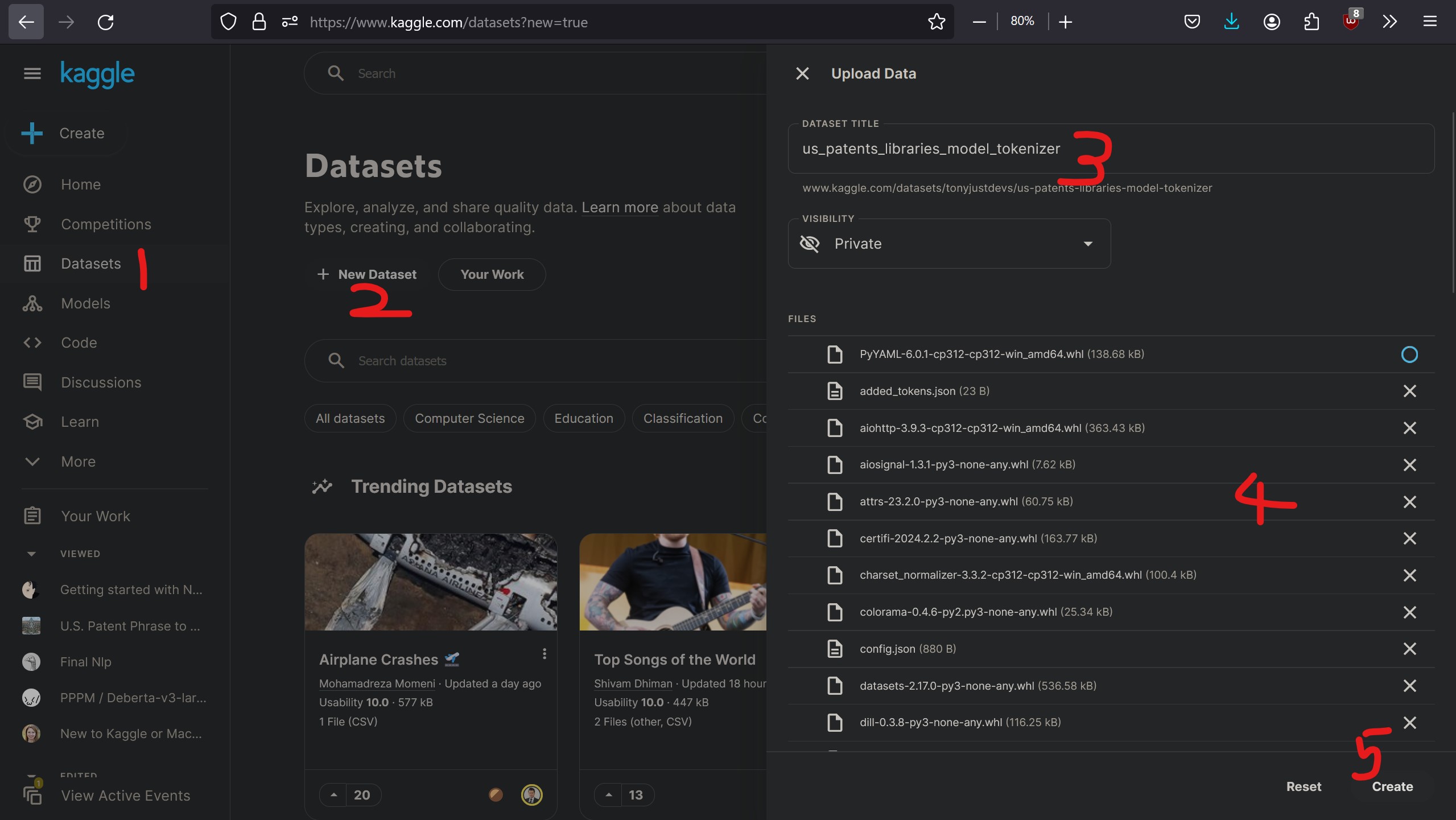
4.3 Load Succesful
Upon completion, a greeting of success should appear.

4.4 Add Data
- Click [Add Data]
- Filter for [Your Datasets]
- Find the uploaded Dataset
5. Code
It’s almost the same code as the previous post so I’ve combined it altogether.
!pip install --no-index --find-links=. transformers
!pip install --no-index --find-links=. datasets
from transformers import AutoTokenizer, AutoModelForSequenceClassification,TrainingArguments,Trainer
from pathlib import Path
from datasets import Dataset,DatasetDict
import pandas as pd
import numpy as np
import datasets
model_nm = "microsoft/deberta-v3-small"
path = Path('/kaggle/input/us-patent-phrase-to-phrase-matching')
mypath = Path('/kaggle/input/us-patents-libraries-model-tokenizer')
tokenizer_uploaded = AutoTokenizer.from_pretrained(mypath)
model_uploaded = AutoModelForSequenceClassification.from_pretrained(mypath)
df = pd.read_csv(path/'train.csv')
df.describe(include='object')
df['input'] = 'TEXT1: ' + df.context + '; TEXT2: ' + df.target + '; ANC1: ' + df.anchor
ds = Dataset.from_pandas(df)
def tok_func(x): return tokenizer_uploaded(x["input"])
tok_ds = ds.map(tok_func, batched=True)
tok_ds = tok_ds.rename_columns({'score':'labels'})
dds = tok_ds.train_test_split(0.25, seed=42)
eval_df = pd.read_csv(path/'test.csv')
eval_df['input'] = 'TEXT1: ' + eval_df.context + '; TEXT2: ' + eval_df.target + '; ANC1: ' + eval_df.anchor
eval_ds = Dataset.from_pandas(eval_df).map(tok_func, batched=True)
def corr(x,y): return np.corrcoef(x,y)[0][1]
def corr_d(eval_pred): return {'pearson': corr(*eval_pred)}
bs = 128
epochs = 2
lr = 8e-5
args = TrainingArguments('outputs', learning_rate=lr, warmup_ratio=0.1, lr_scheduler_type='cosine', fp16=True,
evaluation_strategy="epoch", per_device_train_batch_size=bs, per_device_eval_batch_size=bs*2,
num_train_epochs=epochs, weight_decay=0.01, report_to='none')
model = AutoModelForSequenceClassification.from_pretrained(mypath, num_labels=1,ignore_mismatched_sizes=True)
trainer = Trainer(model, args, train_dataset=dds['train'], eval_dataset=dds['test'],
tokenizer=tokenizer_uploaded, compute_metrics=corr_d)
trainer.train()
preds = trainer.predict(eval_ds).predictions.astype(float)
preds = np.clip(preds, 0, 1)
submission = datasets.Dataset.from_dict({
'id': eval_ds['id'],
'score': preds.squeeze()
})
submission.to_csv('submission.csv', index=False)6. Results
It worked!